
Rise of Stable Diffusion and transformation of Art with AI
AI-based image generation is getting mainstreamed. A newly released open-source image synthesis model called Stable Diffusion is a publicly accessible image generator service that can generate photo-realistic art which mimics human creativity, allowing anyone with a PC and a decent GPU to conjure up almost any visual reality they can imagine. It can imitate virtually any visual style, and if you feed it a descriptive text phrase, the results appear on your screen like magic.
Shopify's AR/VR Product Lead Russ Maschmeyer has demonstrated an interesting and cool prototype service that would allow its users to come up with ideas for real-life wallpapers, preview AI-generated results in AR, and instantly purchase the final product with the exact design a person would want.
1/ As soon as StableDiffusion landed we dropped everything to build a GENIE! 🧞♂️
— Russ Maschmeyer (@StrangeNative) September 13, 2022
🎙 Voice UI
🖼 AI Art
😎 AR previews
🤑 Instant purchasing
📦 On-demand production
Could AI make every shopper’s wish come true? 🤔👇 #ai #aiart #stablediffusion #dalle #dalle2 #vui pic.twitter.com/0rHLH9Y5aI
Stable Diffusion Capabilities
The current capabilities of Stable Diffusion allow any user:
- Convert text into novel images at 512x512 pixels in seconds.
- Use image modification, via image-to-image translation and up-scaling, to transform an existing image into a new image.
- Use GFP-GAN modeling which allows users to upload a blurred face which is then up-scaled or restored.
Example 1:
Prompt: Smog in Lahore
Images:



Example 2:
My daughter love to color, let's see how stable diffusion can help here.
Prompt: Children coloring workbook plants
Images:



How does It work?
Diffusion models work by corrupting the training data by progressively adding Gaussian noise, slowly wiping out details in the data until it becomes pure noise, and then training a neural network to reverse this corruption process. Running this reversed corruption process synthesizes data from pure noise by gradual denoising it until a clean sample is produced. This synthesis procedure can be interpreted as an optimization algorithm that follows the gradient of the data density to produce likely samples.

The database underlying Stable Diffusion is called LAION-Aesthetics. This database contains images that have been embedded with image-text pairs and have been filtered according to their ‘beauty’. Specifically, the database was fine-tuned by AI models trained to predict the rating people would give images when they were asked “How much do you like this image on a scale from 1 to 10?”. This aims to eliminate pornographic and otherwise disturbing content from forming the basis of the AI’s training.
Other Interesting Applications
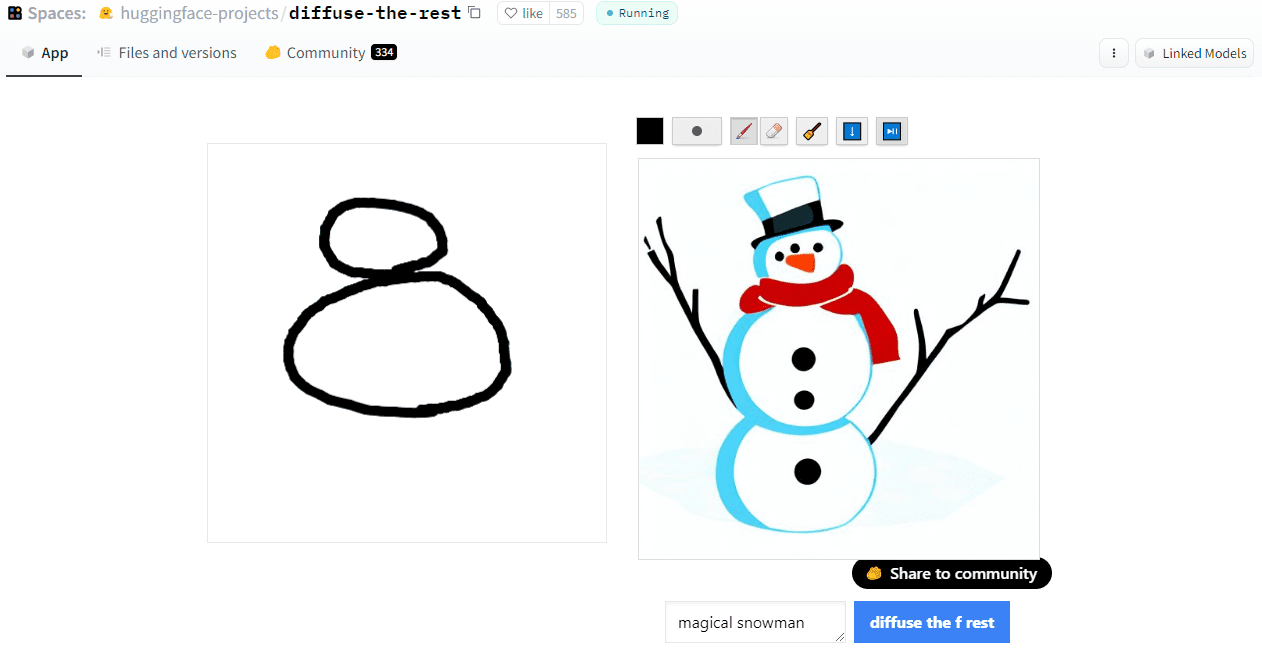
- Diffuse The Rest allows you to draw the painting, and by using the prompt, it generates high-quality realistic art. In the example below, I have drawn two circles and wrote the prompt “magical snowman” to generate high-quality art. You can even go deep and add more lines and color to get even better results.
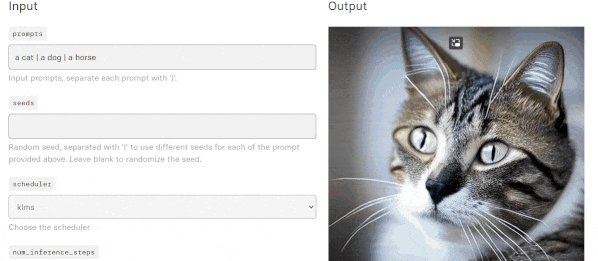
- Stable Diffusion For Videos is an incredible project that takes two or more prompts and blends them to create a video. It looks so genuine. It constructs videos with Stable Diffusion by exploring the latent space and morphing between text prompts.
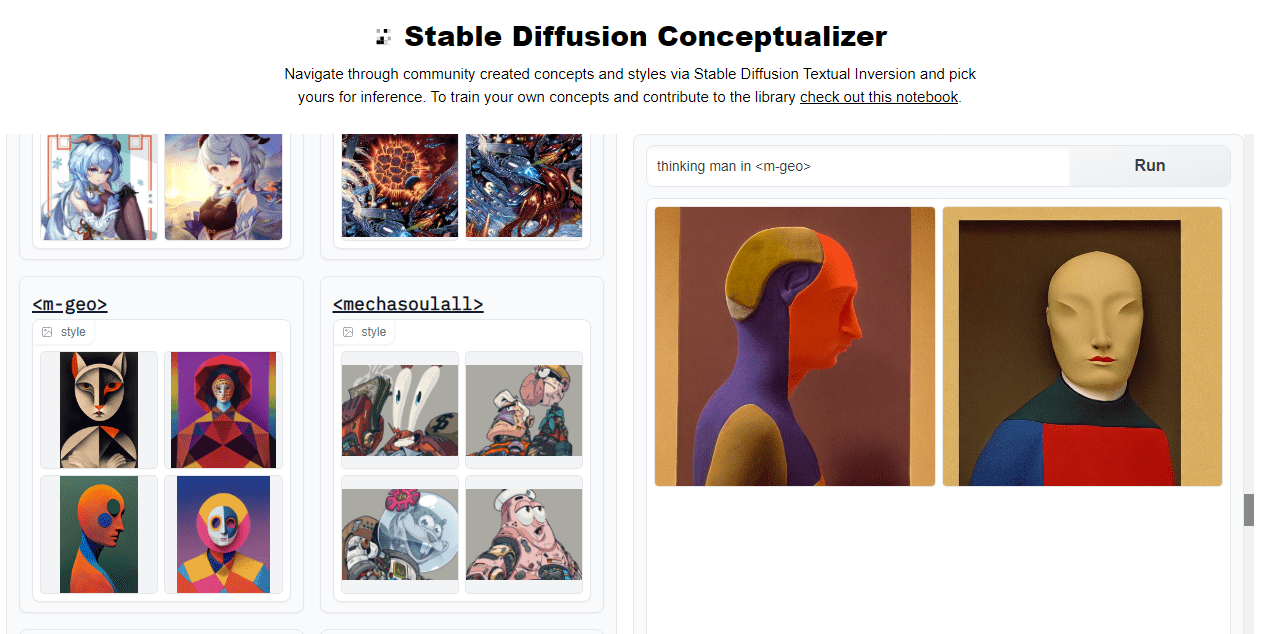
- A Stable Diffusion Conceptualizer uses prompts and style tags to generate the image with a particular art style. You can scroll through all of the various styles and copy past the tag to your prompt and create the masterpiece.
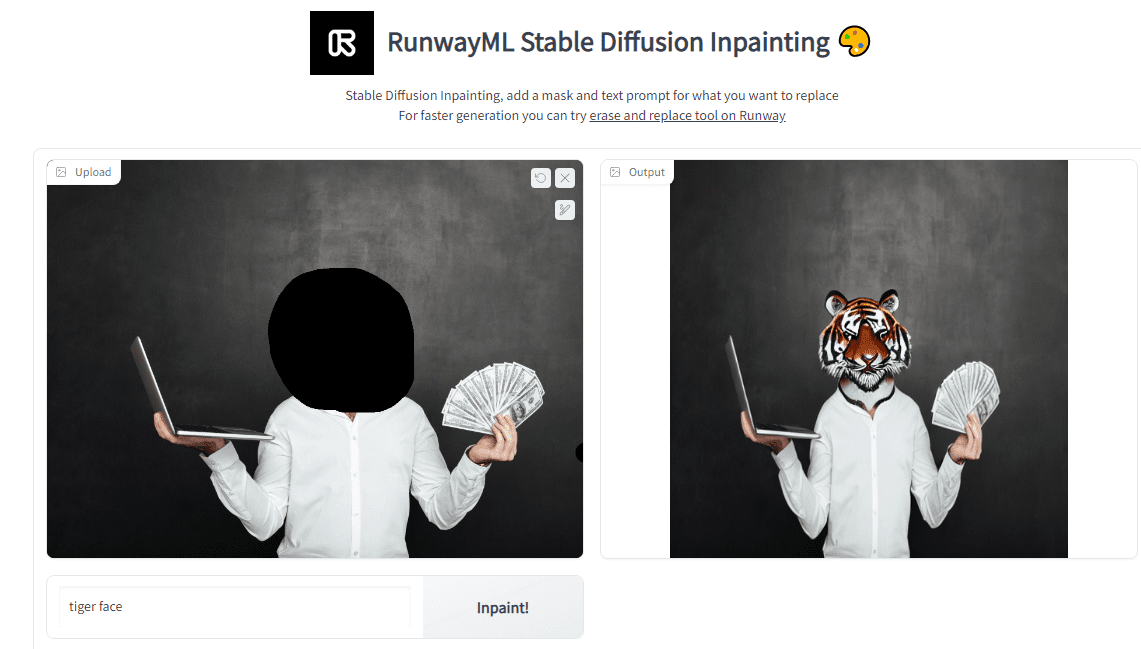
- Runway Inpainting is a simple but powerful tool to remove or replace objects in the image. You can edit images by highlighting and writing prompts. As you can see, The man's face changed with the lion's. It is clean. You can remove the hat, replace shoes, and add objects in images. The possibilities for editing images are limitless.
- Whisper To Stable Diffusion is a handy tool for converting speech to text and using it to generate an image. You can even edit the predicted text to rerun the Diffusion model inference. Instead of writing long prompts, you can speak your mind, and it will produce a high-quality image for you.
Member discussion