
AI Mindset for a successful enterprise data transformation

This post provides the recommended lifecycle for structuring machine learning and AI projects.
I came across many businesses and IT leaders struggling to make investments in AI. Most of the enterprises do not have in-house AI talent hence they engage outside AI consultancy firms for AI use case identification and implementation.
When the consultants propose the use case implementation approach and the deliverables, business leaders struggle to understand the process and the value that the use case is going to generate. This post will explain the AI mindset that enterprise leaders need to adopt to have a clear understanding that AI is different from traditional IT. Secondly, this post will also explain how the AI project should be executed.
AI Mindset
“Machine Learning changes the way you think about a problem. The focus shifts from a mathematical science to a natural science, running experiments and using statistics, not logic, to analyse its results.” — Peter Norvig — Google Research Director
In traditional software engineering, we can reason from requirements to a workable design, but with AI and machine learning, the experiment is necessary to find a workable model.
Traditional software engineering deliverables include:
- Web applications
- Mobile apps
- BI Reports etc.
We have a mature SDLC methodology for this type of work. The exact specifications of the application, sometimes even clickable wireframes are locked before the implementation starts. All stakeholders know exactly what the output is going to be, how it will look like, and how exactly it will behave. But AI does not work like that.
The exact specifications of the AI models like its accuracy, data it will require, and the deployment complexity can’t be fathomed before the implementation. This is why it becomes difficult for enterprises to accept these ambiguous and open-ended deliverables.
Successful AI transformation requires a change in mindset.
Get comfortable with some uncertainty
Will you end up with a usable model? You don’t really know at the start.
In traditional programming, you have set parameters and you understand how everything should behave. With ML, the non-coding work can be very complicated, but you’ll usually write far less code. If you are interested to learn more about traditional programming and AI read this post Software 2.0 by Tesla AI chief Andrej Karpathy
Think Like a Scientist
To address the challenges of transitioning to AI, it is helpful to think of the AI process as an experiment where we run test after test after test to reach a workable model. As in a scientific experiment, the process can be exciting, challenging, and ultimately worthwhile.
Following is the scientific process explained visually.
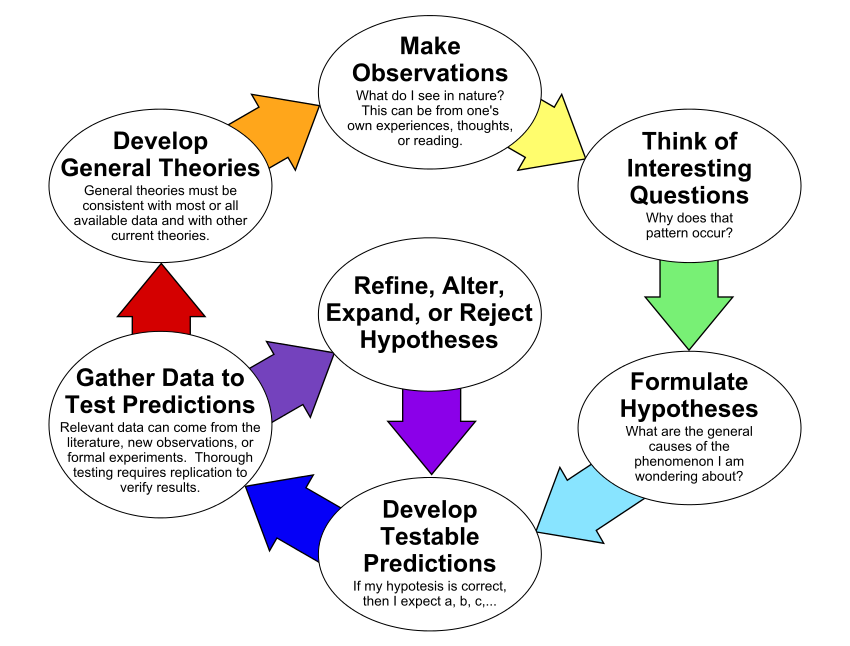
The same scientific process can be mapped on the machine learning process as well.
- Set the research goal. We want to predict how sales of a shoe brand will be on a given day.
- Make a hypothesis. Our sales manager thought the weather forecast is an informative signal, as it influences the shoe sales.
- Collect the data. Our IT people looked at the data they have, or deploy systems to collect historical sales and weather data for each day.
- Test your hypothesis. Our data scientists and AI engineers will train a model using this data.
- Analyze your results. The business owner will evaluate Is this model better than existing systems?
- Reach a conclusion. We should (not) use this model to make predictions, because of X, Y, and Z reasons
- Refine hypothesis and repeat. The type of shoe can be a helpful signal. Incorporate the new data and test the model again. and continue experimenting until the business leaders agree that we have a workable solution that is significantly better than the current forecasting solution.
AI Project Lifecycle
A result-oriented agile approach is recommended to be followed. A Discovery workshop is conducted to prioritize use cases based on technical complexity and business ROI. After this, Minimum Viable Products (MVPs) are developed for testing within 3 months.
Tuning of the solution, integration with data sources, and deployment at scale are done within the next 4 months.
- Use Case Discovery (2 weeks): Help business stakeholders to prioritize use cases based on business challenges, technical feasibility, and data availability.
- MVP Project (2–3 months): Train and deploy a Minimal viable model(MVM) that can be used by the enterprise to meet the goals specified during the use case discovery
- MVP to Scale (3–4 months): Further tune the AI model and Integrate with existing systems and data sources to create an end-to-end retrainable Machine Learning pipeline with integrated model scoring and monitoring using machine learning ops.
Stage 1: Define the AI use case
- Identify and define the AI use case and problems to be solved
- Define hypothesis
- “Hypothesis” = potential pattern we expect to see in data
- Define experiment(s) to validate the hypothesis
- Identify data source(s)
- Agree on metrics to evaluate experiment(s)
Stage 2: Explore data
- Descriptive analysis of the data
- Determine the quality and cleanliness of data
- Explore data through queries and visualization
- Identify patterns, outliers in data
Stage 3: Select algorithm
- Research existing strategies and white papers
- Research existing open-source models that may be used start with, This will ensure a quick-win even if less data is available.
- Select an algorithm based on hypothesis, type of features, patterns in data
- Frame the problem e.g. classification vs. regression
- Supervised vs. unsupervised learning
- Univariate or multivariate
- Time series
- DNN vs. Non-DNN
Stage 4: Do feature engineering
- Use domain knowledge & heuristics to identify features
- Transform raw data into features
- Craft new features as needed
- Remove redundant/duplicate features
- Remove highly correlated features
- Reduce dimensionality as required
- Check for class imbalance
- Check for data leakage
Stage 5: Build AI model
- Split the dataset for training, and test
- Write code for the experiment
- Build a model
- Determine the duration and the amount of data for the initial experiment
- Determine whether the model meets ROI requirements and risk requirements
- Tools: TensorFlow, Pytorch, Sk-learn, Python libraries
- Deliverable: TF code/trained model
Stage 6: Iterate to improve model performance
- Evaluate the model result
- Visualize the model result
- Iterate and Improve the result by hyperparameter tuning
Stage 7: Present results, tell a story from the data
- Present result: use data + visualization + narrative to tell a story
- Tools: Slides, TensorBoard
Stage 8: Plan for deployment
- Make a prediction on production data and build a business case for operationalizing it
- Prepare performance and scale requirements for production
- Prepare operationalization requirements for training and scoring
- Design architecture for model training and retraining
- Design architecture for prediction
- Prepare work breakdown structure
- Develop proposed timelines for training and retraining the model
- Prepare a plan for rollout and the success criteria for increasing traffic.
Stage 9: Deploy and operationalize the model
- Convert the model into an API
- Build dataset training and scoring architecture
- Operationalize the model in business application(s) for seamless integration of AI with the current business process
- Build an automated test
- Build the feedback loop
Stage 10: Integrate with business and monitor
- Business process reply on the ML model
- Data analysis and feedback loop
- Model changes with data
The adaptation of the AI mindset and an iterative AI journey will ensure that AI investments are properly executed and more resources are put into the bets that are proven to work in the MVP phase.
Member discussion